Comparison of Various CNN Models in Railway Accident Prevention System
Ziyu Fang, Pyeoungkee Kim
Computer Software Engineering Department, Silla Univ.
140 Baegyang-daero (Blvd), 700beon-gil (Rd.), Sasang-Gu
Busan, Korea
FangZi327@Gmail.com, pkkim@silla.ac.kr
Abstract
In this paper, we are trying to determine which of the latest CNN models and algorithms are more suitable for railway accident prevention systems. We use MobileNet v2 using Single Shot Detector algorithm, MobileNet v1 using Feature Pyramid Network algorithm and MobileNet v1 using Single Shot Detector algorithm as a reference. After training and evaluation, MobileNet v1 using Feature Pyramid Network algorithm is the most suitable model for Railway Accident Prevention System. And this model is particularly good at small target recognition.
Keywords-component; railway accident, image recognition, deep-learning
1. Introduction
As well as everybody knows, the overpressure in the air when a train passes with high-speed will cause a serious damage to people near the rails. According to previous research, MobileNet version 1 model has a good recognition effect on the Railway Accident Prevention System. Now the new model named MobileNet version 2 has been designed and tested. Not only that but the Single Shot Detector algorithm (SSD) was used before. Now we have added a new algorithm named Feature Pyramid Network (FPN). In order to determine which algorithm is the most suitable for the system, the experiment was re-executed.
2. The CNN Models in Railway Accident Prevention System
We used the previous design to capture image near the rails in the air over the 30 meters by the drone. And let the computer identify the target if someone was near the rails. MobileNet v1reduced the size of the model and improved the recognition efficiency by using depthwise separable convolution instead of standard convolution [1]. MobileNet v2 use a 1*1 pw to increase the number of channels and get more features. At last use linear bottlenecks instead of ReLU to prevent the features damage as shown in Fig.1 [2].
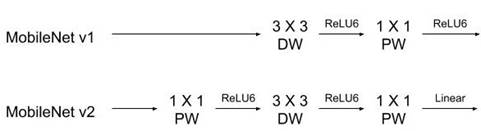
Fig. 1 Differences between MobileNet v1 & v2
SSD algorithm does not perform upsampling and only extracts features of different sizes at different layers for prediction without adding extra calculations as shown in Fig.2 [3]. But, there are different sized targets in the image, while different targets have different features. Simple features can be distinguished by using the features of shallow layers. And the features of deep layers can be used to distinguish complex targets. FPN is characterized by the simultaneous use of shallow and deep features to better identify targets [4].
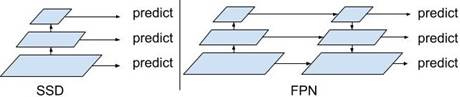
Fig. 2 Single Shot Detector & Feature Pyramid Network
There are 1123 images in the experiment dataset with the PASCAL VOC format. There are 919 training images, and 204 evaluation images. As shown in Fig.3, the dataset does not only collect the images with various drone flight states, but also various background and environment. We use the human body in different positions near the rail as the target of recognition. The dataset includes images of different genders, as well as images of different poses. We record the input rectangle’s corner pixel value (xmin, ymin, xmax and ymax) and save them into tfrecord file.

Fig. 3 Image Example
3. Experiment Result
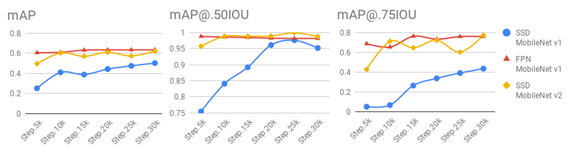
Fig. 4 mAP & mAP with different IOU
As shown in the Fig.4, when the IOU is 0.5, the mAP of the SSD MobileNet v2 model is close to 1. And the mAP of SSD MobileNet v2 is better than the other two models. When the IOU is 0.75, the mAP of SSD MobileNet v2 is not as good as the mAP of the FPN MobileNet v1 model. The performance of the FPN MobileNet v1 model is best considering the different IOU situations.
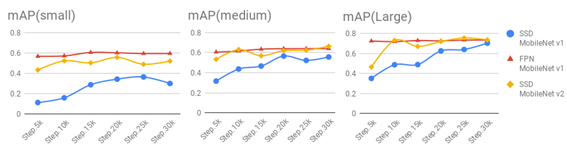
Fig. 5 mAP with Different Target Sizes
As shown in Fig.5, the FPN MobileNet v1 model also performs well for targets of different sizes. Although the mAP difference between the FPN MobileNet v1 model and the SSD MobileNet v2 model is not significant, it is significantly better than the SSD MobileNet v1 model. However, the small target recognition performance of the FPN MobileNet v1 model is better than the performance of SSD MobileNet v2.
4. Conclusion
This article uses some new CNN models. By comparing several sets of experimental data, the FPN MobileNet v1 model is the most suitable model for Railway Accident Prevention systems. The model's target accuracy is high, especially for small targets. In the future, we will continue to develop systems for railway safety.
References
[1] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam (2017) “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” arXiv:1704.04861
[2] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen (2018),"MobileNetV2: Inverted Residuals and Linear Bottlenecks", arXiv:1801.
[3] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg (2016), "SSD: Single Shot MultiBox Detector", arXiv:1512.02325
[4] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie (2017), "Feature Pyramid Networks for Object Detection", arXiv:1612.03144